5. Conclusions
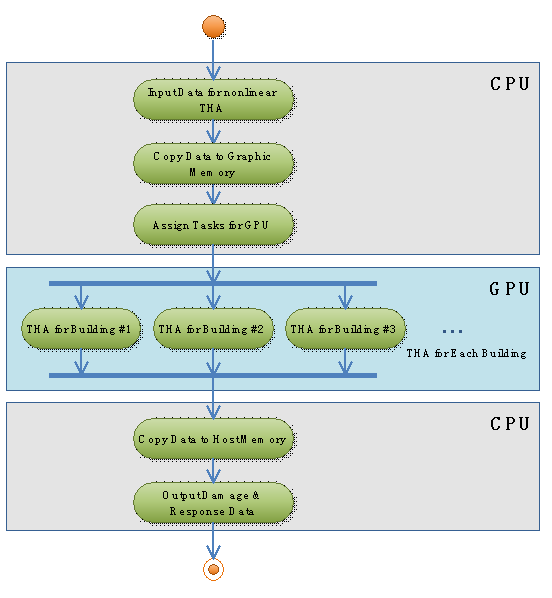
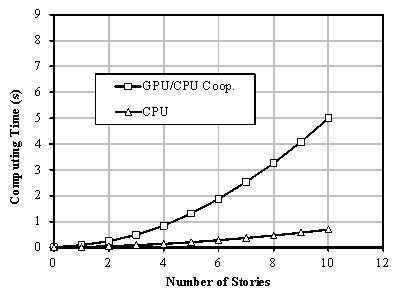
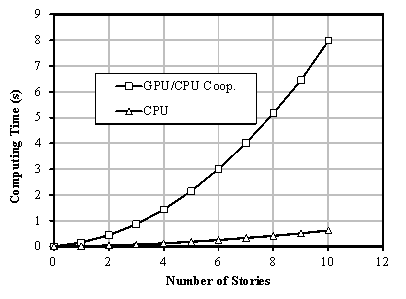
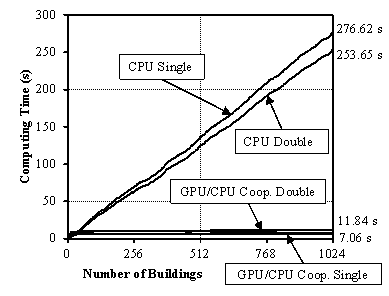
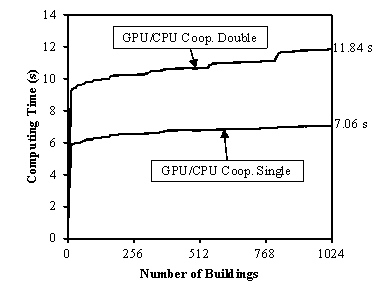
It has been demonstrated that the performance of the proposed approach for seismic damage simulations of urban regions based on GPU/CPU cooperative computing is very high. The performance-to-price ratio can be 39 times as great as that of a traditional CPU approach, leading to a very significant difference in computing time for seismic simulations for real large cities.
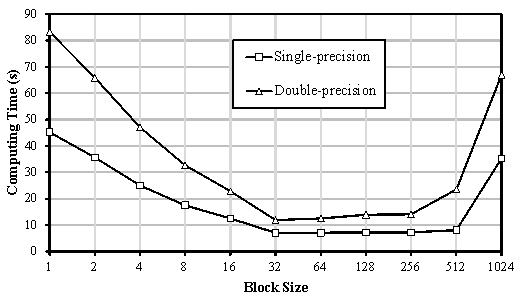
According to the benchmark, single-precision float computing is recommended in this approach because of the higher performance and lower memory required compared with when double precision is used. The accuracy requirements of urban seismic damage simulations can be satisfied by both single precision and double precision.
The influence of velocity pulses can be considered in the proposed approach. Furthermore, the damage locations, which are greatly significant to loss estimation, can also be obtained using the proposed MCS model.
It should be noted that this work is the first trial to implement the regional seismic damage analysis based on GPU/CPU cooperative computing, and significant progress has been obtained. Further improvements, such as more accurate inter-story hysteretic behavior for the MCS model and more rational soil/site models, will increase the accuracy of the prediction. All these improvements can be implemented on the proposed program architecture, which indicates the significant potential of the proposed method.
Appendix A. Inter-story model of regular buildings
The buildings in an urban region are divided into different groups according to their structural types and heights. For regular buildings, the 19 building types proposed in HAZUS [7] are adopted, as shown in Table A1. For some special buildings, for which the performance is quite different from that of regular buildings, the inter-story behavior can be determined using a detailed structural analysis, as demonstrated in Appendix B.
A.1. Inter-story hysteretic model
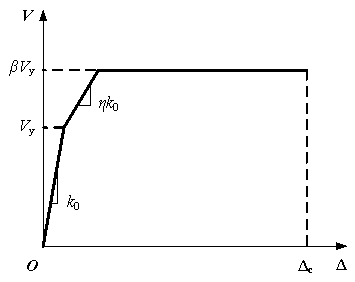
The trilinear backbone curve proposed by HAZUS [37] is adopted in this study to describe the backbone curve of the inter-story behavior (as shown in Figure A1), which represents the elastic, yielding, and fully plastic stages. There are 5 parameters in the backbone curve: K0 (the initial lateral stiffness), Vy (the inter-story shear yield strength), ¦Ç (the hardening ratio), ¦Â (the ratio of peak strength to yield strength), and ¦¤c (the inter-story drift of the complete damage state, which determines the collapse state of the story).
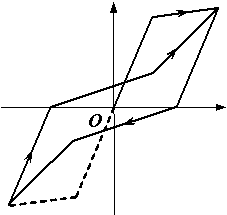
Three different inter-story hysteretic models are adopted in this study according to the structural types of the buildings. The widely used Modified-Clough model [44] , shown in Figure A2a, is capable of modeling reinforced concrete frames that fail because of flexural failure [45¨C47] . Thus, this model is selected in this research to represent the concrete frame structures (i.e., C1 in Table A1).
Another commonly used model is the bilinear elasto-plastic model (Figure A2b), which can be used to represent conventional steel moment frames [46, 48] . Thus, this model is also used here to model steel frames (i.e., S1 and S3 in Table A1).
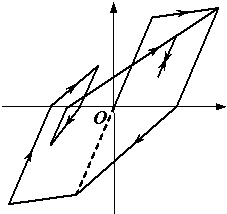
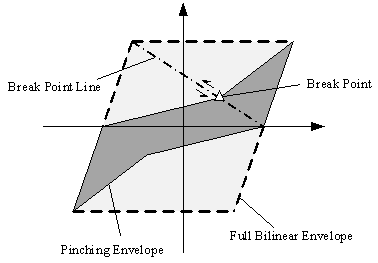
For those structures in which shear failure is most significant, a pinching model (Figure A2c) is an appropriate choice for the simulation [49¨C51] . The commonly used pinching model proposed by Steelman & Hajjar [30] is adopted in this study. In this model, the unloading stiffness is constant and equal to the initial stiffness. All possible break points in the reloading curve are located on the straight ˇ°break point lineˇ± from the intersection of the unloading path with the horizontal axis to the yield point of the full bilinear hysteretic loop in the loading, as shown in Figure A3. Thus, only one parameter, ¦Ó, is required to determine the hysteretic behavior of the model, as shown in Eq. (A.1)
![]() ,
(A.1)
,
(A.1)
in which Ap and Ab are the areas of the pinching envelope and full bilinear envelope, respectively (Figure A3). ¦Ó is a coefficient used to quantify the severity of degradation. The reason for choosing this model is that the pinching parameter ¦Ó can be easily determined by the degradation factor ¦Ę given in Table 5.18 of HAZUS [30, 37] . If another pinching model (e.g., the Ibarra pinching model [52] ) is adopted, the calibration of various parameters is very difficult and ineffective for regional seismic analysis. This model is adopted for all the structural types in this research except C1, S1 and S3.
A.2. Parameters for the inter-story hysteretic model
For most buildings in urban areas, the first and second modes primarily determine the seismic response [38] . The periods of the buildings are determined using Eq. (A.2) [28, 53] :
![]() ,
(A.2a)
,
(A.2a)
![]() ,
(A.2b)
,
(A.2b)
where T1 and T2 are the first and second vibration periods of the specific building, respectively, N is the number of stories of the specific building. N0 and T0 are the number of stories and fundamental period, respectively, of the typical buildings presented in Tables 5.5 and 5.7 of FEMA [37] .
For regular buildings, the initial inter-story stiffness and the mass of each story are uniformly distributed along the height of the building [28] ; then, the stiffness and mass matrices of the MCS model are:
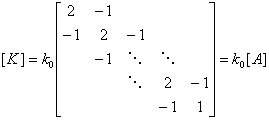 ,
(A.3)
,
(A.3)
 .
(A.4)
.
(A.4)
Hence, the natural frequency of the fundamental mode is [38] :
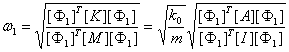 ,
(A.5)
,
(A.5)
where [¦µ1] is the modal vector of the fundamental mode. If [K] and [M] are determined, [¦µ1] can be easily determined using a generalized eigenproblem analysis [38] . For a building with uniform mass and lateral stiffness in each story, [¦µ1] will not change with k0 or m, so [¦µ1] can be determined with assumed k0 and m.
Therefore, the initial inter-story shear stiffness is:
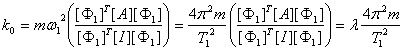 ,
(A.6)
,
(A.6)
where:
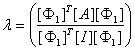 ,
(A.7)
,
(A.7)
Thus, the inter-story backbone curve parameters of story i in Figure A1 are determined as follows:
![]() ,
(A.8a)
,
(A.8a)
![]() ,
(A.8b)
,
(A.8b)
![]() ,
(A.8c)
,
(A.8c)
![]() ,
(A.8d)
,
(A.8d)
![]() ,
(A.8e)
,
(A.8e)
where m is the mass of each story, which
is determined based on the area of the floor and the function of the building
[15] . g is the acceleration of gravity. ![]() is the inter-story drift
ratio at the threshold of the complete damage state, which is suggested by HAZUS [37]
. h is the story height. (SDy, SAy), (SDu,
SAu) are the yield capacity point and the ultimate capacity point,
respectively, of the capacity curve suggested by HAZUS [37]
, which is a function of the design intensity and constructional period.
is the inter-story drift
ratio at the threshold of the complete damage state, which is suggested by HAZUS [37]
. h is the story height. (SDy, SAy), (SDu,
SAu) are the yield capacity point and the ultimate capacity point,
respectively, of the capacity curve suggested by HAZUS [37]
, which is a function of the design intensity and constructional period.
![]() is the mode
factor suggested by HAZUS [37]
.
is the mode
factor suggested by HAZUS [37]
. ![]() is the ratio between
the inter-story shear strength of the ith story (
is the ratio between
the inter-story shear strength of the ith story (
![]() ) and that of the ground story
(
) and that of the ground story
( ![]() ), which is calculated as
follows:
), which is calculated as
follows:
![]() .
(A.9)
.
(A.9)
The relationship
between the design seismic load of the story and the altitude of the story above
ground level is approximately linear in Chinese building codes [43]
. Futhermore, the design inter-story shear strengths of the story and
the sum of lateral load of the above stories can also be considered as linear
relationship. Thus, ![]() can be expressed as:
can be expressed as:
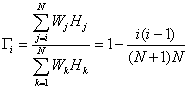 .
(A.10)
.
(A.10)
in which
![]() and
and ![]() are
the weights of stories j and k, respectively.
are
the weights of stories j and k, respectively. ![]() and
and ![]() are the
altitudes of stories j and k above ground
level, respectively. A similar method is also
used by other researchers [54] .
are the
altitudes of stories j and k above ground
level, respectively. A similar method is also
used by other researchers [54] .
The empirical values of the damping ratio for Rayleigh damping [38] are estimated according to the structural type of the building, as given in Table A2.
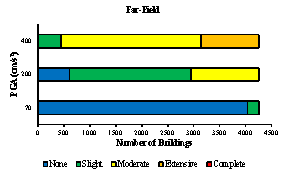
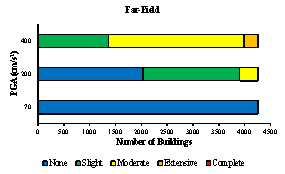
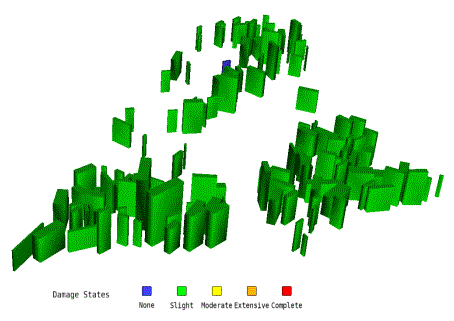
The damage states for regular buildings are identical to the damage states defined by HAZUS: slight, moderate, extensive, and complete. The inter-story drift ratio is adopted as the threshold of each structural damage state, and the values for the 19 structural types are based on Table 5.9 of HAZUS [37] .
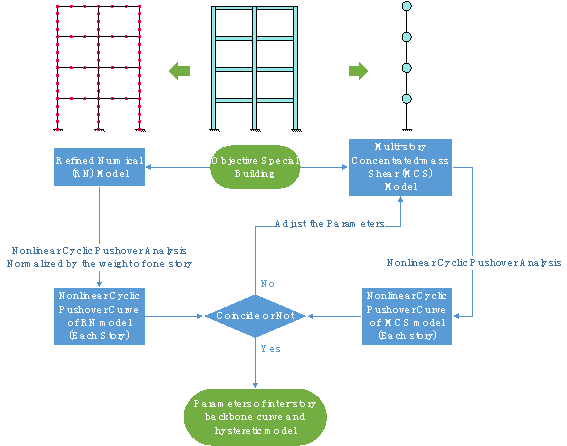
Appendix B. Inter-story model for special buildings
Parameters of the inter-story backbone curve and hysteretic model for special buildings are obtained using pushover analysis. Figure B1 presents the process of the method. The pushover analysis can be implemented using more detailed numerical models (such as the fiber beam element model or the multi-layer shell model [31, 55¨C57] ) according to the structural design data.